Before You Let the Agents Run Wild
The ROI from agents won't come from deploying them quickly. It will come from understanding their quirks, getting the basics right, and mastering how to trust them.
The agent gold rush is upon us
ChatGPT launched in November 2022 and AI has dominated the enterprise IT conversation ever since. The following three years have been a frenzy: AI strategies, RAG chatbots, reasoning models, coding agents, MCP servers, and the SaaS-Pocalypse to name just a few.
The pie is large, with some analysts estimating the market value to be $3 trillion to $5 trillion. Agents don't need to be perfect, they just need to be good enough to convince a decision-maker they are good enough. But what does that mean?
Let's start by trying to define what "agent" means. For me, agents do three primary things: respond to input (a chat message, business event, timer, etc.), "reason" using LLMs guided by various prompts, and invoke tools that may have real side effects such as writing to a database or sending an email. This happens in a loop that results in generative output, which may include a request for human interaction:
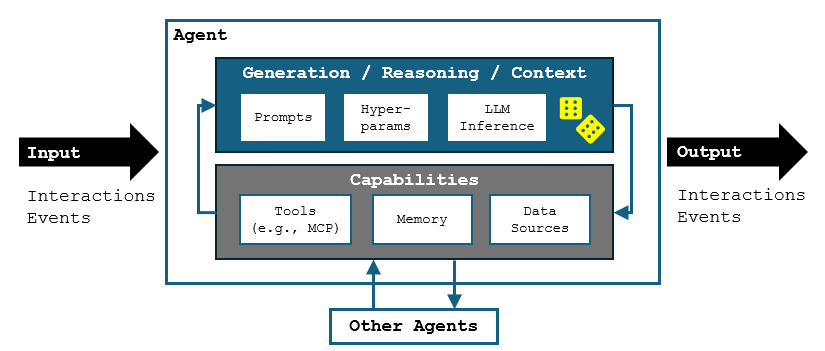
Inference is how the decisions are made in this loop, which are probabilistic (hence the yellow dice). The LLM makes them the same way it generates text, by predicting the next token:
Context Window: "Mary had a little "
Next Token: "lamb" = 99%, "submarine" = 0.1%, ...
Armed with these concepts, what do we need to be mindful of when trying to use agents?
Treat agent-based automation as an amplifier of current behavior
Software engineers, for many deep reasons, are early adopters of agents for their use cases. It's common in 2026 to find a software engineer managing a swarm of agents working in parallel 24x7, even while best practices are nascent. Tech startups are quick to point out how they are going all-in on this new way of working, but they are working from a clean sheet of paper, enterprises are not.
The 2025 State of AI-assisted Software Development report from the DORA group at Google makes the strong argument that applying such automation acts as an amplifier: organizations that previously struggled with quality or process issues will face much more of the same, and organizations that had good fundamentals were more likely to succeed.
A 10x louder speaker system is unlikely to improve the music your band is currently playing.
Not all business processes are the same as software development, but any sudden change of throughput can logjam a process if you are not prepared.
At a minimum, it's worth measuring your current manual process before you bring in the agents. How happy are you with the throughput and quality of your processes and products today? Of course it's unrealistic to "fix everything" before you let in the agents. Start by ensuring you have sound flow and quality measurements in place (e.g. change failure rate, cycle times), monitor for upstream and downstream bottlenecks, and carefully manage risks as you roll out the agents.
Don't use agents when they are not necessary
Agents are not the only answer and don't need to be. That statement is almost heretical in 2026.
It may be tempting to think that agents are a shortcut to get automation without needing to engage IT. This is especially true when there is a history in your company of modest IT project proposals being rejected due to poor ROI or opportunity costs.
Why spend time building a solution when I can give an agent some basic prompts and tools and let it figure out the rest?! That makes sense, especially since agents are good at problem-solving when things don't go well, but this approach comes with important trade-offs.
Traditional solutions (scripts, apps, APIs, data pipelines) are ideal when the rules are clear and the cost of failure is high. Once constructed, these deterministic systems are relatively understandable, static, and reliable, if properly maintained.
Agents are ideal when the rules are less clear, the cost of failure is low, there is a need to learn over time, or you need to generate data (summaries, analysis, ideas). These probabilistic systems come with additional costs and risks, many of which are emerging.
The biggest misconception I've seen so far is that agent failures are problems that can be solved with system prompts, tweaking certain hyper-parameters, and backstopping with evaluation tests. These are all necessary, but ultimately the best you can hope for is a low probability of errors.
Before deploying agents, the question is not "will it work?"; the question is "what percentage of the time can I afford this not to work?" Every situation is different, but even modest business processes tend to require high enough reliability to rule out any probabilistic systems and the costs of compensating controls.
This is where concepts like trust come into play, which I explain next.
The good news is that the long tail of modest traditional IT projects that never made the cut in the past may now be feasible thanks to, you guessed it, coding agents.
Master how to trust agents
The simple and conservative approach to managing agent risks is to require a human-in-the-loop to approve all decisions that may have a meaningful side effect, but this approach does not scale and is likely to result in rubber-stamping.
The companies who learn how to trust these new actors will be the ones who capture the most value from them. This is less about technology and more about dull topics like risk management, accountability, and strategic thinking. Here are four things to focus on.
1. Treat LLM and agent projects like data projects, not like applications
Building applications is not easy, but once they have stabilized, they are what they are. An agent may seem like an application, but they have very different costs, risks, lifecycles, and behaviors:
- The "brain" of the agent is an LLM that will change very often; it may have a lifespan of only about six months.
- The prompts in your agent are likely optimized for a specific model and will require frequent maintenance with regression tests.
- The data the agent pulls into their context window is likely changing all the time.
- The harness or orchestrator you are using to manage the agents is also changing.
This river of change is the norm for data projects, where the biggest concerns tend to focus on managing the four V's of data: volume, velocity, variety, and veracity and how those change over time. Data projects tend to require more experimentation and are more difficult to estimate for this reason. LLM/ML projects and MLOps have special capabilities to handle data/model drift issues.
If you treat LLM projects with a data project mindset, you will be better positioned to establish long-term trust in your system.
2. Assess risks based on multiple dimensions
A one-size-fits-all approach to agent governance is likely to become a bottleneck. Adaptive governance methods classify systems into different risk categories before applying any controls to balance agility with control. It's wise to use a similar approach for agents by taking multiple dimensions into account when assessing the risks:
- Scope: Is this used by one person or the whole company? Does it require access to sensitive data or large quantities of information? Does it answer questions on behalf of a small team or an entire division?
- Complexity: Does it have a few inputs and use a few tools, or dozens, or hundreds?
- Side-effects: Does this perform reads or writes? Does it send emails, update externally-facing content, or alter production infrastructure? Is it likely to cause an unintentional denial-of-service attack on its dependencies?
- Autonomy and accountability: Is this fully autonomous, or do some decisions require human intervention? Which ones and why? Who is accountable for the decisions being made autonomously?
All of these dimensions can change over time, sometimes without needing to deploy changes to the system. For example, new capabilities in an MCP server dependency may change the agent's context window enough to change its behavior. Therefore, assessments must be performed continuously.
3. Be mindful of compounding risks
There was a time when "computers" were teams of people performing huge sets of calculations by hand. The stakes were high for these computers, working on things like ballistic trajectories of artillery for the US Army in World War II. The risks of human errors compounded at every step, and every calculation had to be carefully verified. As demands on these human computers increased, these compound risks and mitigations became a crisis, and gave rise to the ENIAC and the EDVAC: the first general purpose computers of their kind, and the prototypes of the computers we use today.
Ironically, the compounding risks of those human computers are the same challenge today with agents. If you have just three agents all working at a 90% success rate (which is high), their combined success rate is only 73%. Such compound success rates can be difficult to calculate as the number of agents involved changes and as those agents internally change on their own timelines.
4. Emphasize auditability and centralized control
The path to ROI for agents comes down to the ability to make decisions and take actions that have real side-effects, such as a customer support agent with the authority to issue refunds.
No system prompts you can implement today will ensure all current and future decisions are sound, especially in the face of so much change and 24x7 activity. Instead, focus on these controls:
- Ensure that all nontrivial decisions made by an agent are documented and auditable. If you don't currently have a regulatory need for this, do it anyway for improved debugging.
- Require a kill switch so that rogue agents can be quickly stopped. Their capabilities, speed, and scale will likely not afford time for committees or negotiations.
- Apply zero-trust and least-privilege security as you should for human users, but tighten it by granting access to specific operations for short periods of time. Humans would likely not tolerate that, but agents will.
- Invest heavily in observability and FinOps
Ok, so... now can I let the agents run wild?
Expect to see a wave of agent governance frameworks, tools, standards, and best practices emerge in 2026 and 2027 because these concepts are very new to most people and the pressure to deploy them is too high. Until then, capturing the most value from agents will depend on a sober understanding of their capabilities and limitations. That will require the will to slow down long enough to ask the right questions before thousands of agents are diligently working 24/7 in your company.
We may be a decade away from getting those unresolved economic, political, and regulatory questions answered. Until then, treat agents like high-voltage power: do not energize the system until the wiring is sound, the breakers are tested, and someone can cut power when something goes wrong.